
优化深度神经网络
正则化
L1正则化
其中表示模型的参数,是正则化强度的超参数。
L1正则化倾向于产生稀疏的参数矩阵,即许多参数被推向零,从而实现特征选择。
L2正则化
其中表示模型的参数,是正则化强度的超参数。
L2正则化倾向于减小参数的绝对值,但不会将其推向零,从而防止过拟合。
在实践中我们往往选择使用L2正则化,以免模型过度依赖某一个参数.
l2_norm = 0.0
for param in model.parameters():
l2_norm += torch.norm(param, 2) ** 2
loss = criterion(outputs, labels) + lambda_l2 * l2_norm一般lambda_l2取值在1e-4到1e-2之间很小的系数,最终加到loss上。
指数加权平均
指数加权平均(Exponential Moving Average, EMA)是一种用于平滑时间序列数据的技术。它通过对过去的数据点赋予指数衰减的权重来计算平均值,从而更关注最近的数据点。 公式如下:
越小,指数衰减越 厉害 .
在上述公式中,我们可以设定的参数: 为初始值,通常取第一个数据点的值。 为平滑因子,取值范围在0到1之间。较小的值会使得平均值对过去的数据点更加敏感,而较大的值则会使得平均值更加平滑。
改进指数加权平均
当初始设置等小的值时,前几个值会被低估,和实际值偏差较大。 如果计算的序列很长,约到后面的加权平均,的影响会逐渐减小,可以通过以下公式进行修正:
更准确地反映当前数据点的趋势。
在除以后,前几个值的偏差会被修正,使得指数加权平均在初始阶段更加准确。随着的增加,修正项趋近于1,对结果的影响逐渐减小。
动量梯度下降
之前的问题:训练震荡、局部最优
作用:加速收敛,减少震荡
更新过程
根据 加权平均 的思想,每个batch更新:
(其中 为变量,为指数加权平均值)
(其中 为学习率)
一般取值在0.9左右。
RMSProp 优化器
原来的训练时,所有的参数都是用同一个学习率。会导致有的参数梯度大,有的参数梯度小。
如果设置lr过大,会导致梯度大的参数在最优解附近来回震荡;lr过小,会导致梯度小的参数更新缓慢,难以收敛。
RMSProp 通过对每个参数使用不同的学习率来解决这个问题。具体做法是对每个参数的历史梯度平方进行指数加权平均,然后用这个平均值来调整学习率。
以参数为例:
计算指数加权平均值:
然后更新:
是一个很小的数,防止分母为 0。
Adam 优化器
它同时考虑了动量梯度下降和RMSProp的优点。
然后计算一阶矩估计(动量):
计算二阶矩加权平均值:
在这里,取,。
然后更新:
是一个很小的数,防止分母为 0。
权重衰减
它也是一种正则化技术,是在模型训练中防止过拟合的技术。
思想很简单,每一次梯度更新参数,同时缩小参数值,防止绝对值过大。
它和L2正则化本质上相似,不同的是L2正则化是通过在损失函数中添加参数的平方和来实现的,而权重衰减则是在每次参数更新时直接缩小参数值。
具体的做法为:
其中是权重衰减系数,通常取值较小,如1e-4或1e-5。如果模型过拟合现象比较严重,就设置大一些
pytorch实现方式:
optimizer = option.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)(同步设置weight_decay参数即可)
权重衰减和L2正则的关系
虽然标准梯度下降效果是一样的。
但是,对于Adam优化器来说,权重衰减和L2正则化的效果是不一样的。 因为添加在Loss里的L2正则,梯度经过动量和平方根调整,已经和直接减小参数值产生了不同
DropOut
DropOut
它也是解决过拟合的一种方法,它是简化网络结构进行正则化。
我们本来是 全连接 神经网络,每一层的神经元都和下一层的神经元全连接。
在这里,训练阶段,dropout会参照超参数p的设置,随机禁用一些神经元。被禁用的神经元不接受输入和输出,一般它应用在隐藏层。
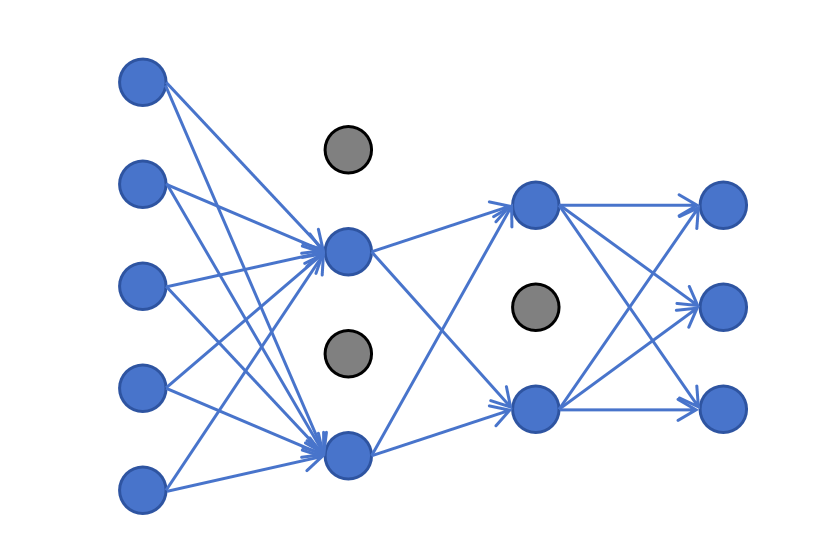
提示
注意: 训练阶段禁用神经元,神经元的输出要除以1-p,以保持输入加权累加期望值不变
在pytorch定义也很简单,直接在nn.Sequential里添加nn.Dropout(p)即可。
p的值我们一般取0.1-0.5,p越大,正则化效果越强。
相关信息
注意:
Dropout在训练和推理阶段行为不同,所以在训练和推理前一定要调用model.train()和model.eval()来切换模式。