
3.knn回归
计算周围的点对某个未知点影响,预测这个值.
import numpy as np
# 预测任务
data_X = [
[1.3,6],
[3.5,5],
[4.2,2],
[5.1,4],
[6.3,3],
[7.2,1],
[8.1,5],
]
data_y = [0.1,0.3,0.5,0.7,0.9,1.1,1.3]
X_train = np.array(data_X)
y_train = np.array(data_y)
X_train.shape, y_train.shape运行结果
((7, 2), (7,))
from matplotlib import pyplot as plt
new_p = [4,5]
new_p = np.array(new_p)
plt.scatter(X_train[:,0],X_train[:,1],color='red',marker='o')
for i in range(len(X_train)):
plt.annotate(y_train[i],xy=X_train[i],textcoords='offset points',xytext=(0,10))
plt.scatter(new_p[0],new_p[1],color='blue',marker='^')
plt.show()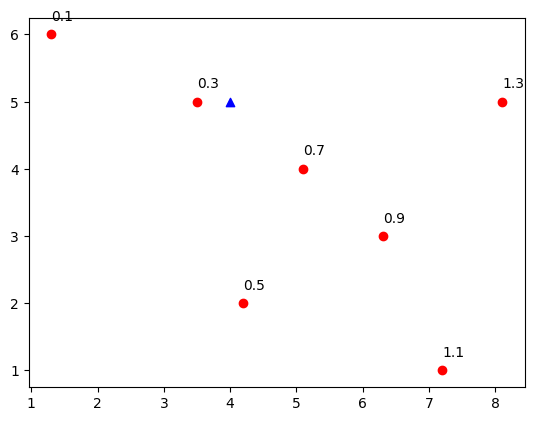
from sklearn.neighbors import KNeighborsRegressor
kr = KNeighborsRegressor(n_neighbors=3)
kr.fit(X_train,y_train)
y_predict = kr.predict(new_p.reshape(1,-1)) # 转换为一行的二维数组
y_predict运行结果
array([0.36666667])
使用Boston房价数据集
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()X = housing.data
y = housing.targetX.shape,y.shape运行结果
((20640, 8), (20640,))
from sklearn.model_selection import train_test_split
train_ratio = 0.7
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=train_ratio, random_state=42)from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(
p=2,
n_neighbors=5,
weights='distance'
)
knn_reg.fit(X_train,y_train)
knn_reg.score(X_test,y_test)运行结果
0.6752803565659038
可以看出,虽然knn更适合用于分类问题,但是对于回归问题,也可以使用knn算法,但是效果并不是很明显